My English Reading Flow —— Collection
The third in a series
1825 Words … ⏲ Reading Time: 8 Minutes, 17 Seconds
2023-04-13 01:58 +0000
这是My Reading Flow (For English Source)系列博客的第三篇
讲完了如何阅读,下面来聊聊整条flow的最后一个环节,Collection — 对读过的文章进行收录。其实在第二部分Read中,我当时就谈及了一些关于收录的事情。
但是必须要说的是,Collection并不是一个阅读流中必不可少的环节。像有很多朋友觉得这些不过是伪需求,疲于形式。但就像我在之前的Q&A中谈到的一点我的理解(很主观):纵使你真的不会再想起这些你收录的内容(当然,你有很大的可能会有用得到它们的时候,它相当于为你读过的信息加上索引,方便你回顾、引用,这是它的实际意义),收录行为也会为你的阅读带来完整性,完整性又带来仪式感,这些都潜移默化地强化着你的阅读体验,帮助你日复一日养成阅读的习惯,明晰阅读的意义(算是种精神意义吧)。
而特别对于像我本人这种有点收藏癖的情况,看着被填得满满当当的database,真的很爽啊拜托!
在明确了Collection并不是一项可有可无的工作后,来聊聊我是怎样做收录的。
对于前文谈到的两种不同的阅读模式,我分别在Notion中建了两个不同的Database来实现信息的收录。大名鼎鼎的Notion自然不必多介绍,它特有的database功能很适合完成这项工作:选择为数据库添加不同种类的view可以清晰地展示信息,利用好Filter和Sort两种工具可以帮助我很好的完成对信息的检索和二次利用。
当设计并部署好适合自己阅读的数据库后,这其实算是件一劳永逸的事情,你后期需要做的只是把文章填加进来就好。
Database1 (For Reading Type1)

Database1 TableView

Database1 BoardView
如图所示,在Database 1 “Jornal List” 中,我作了如下设计:
- Property
- Title:文章标题
- From:文章出处
- Date:开始阅读的日期
- Category:文章分类
- Words:link单词汇总的pdf文件(由Eudic的生词本自动生成)
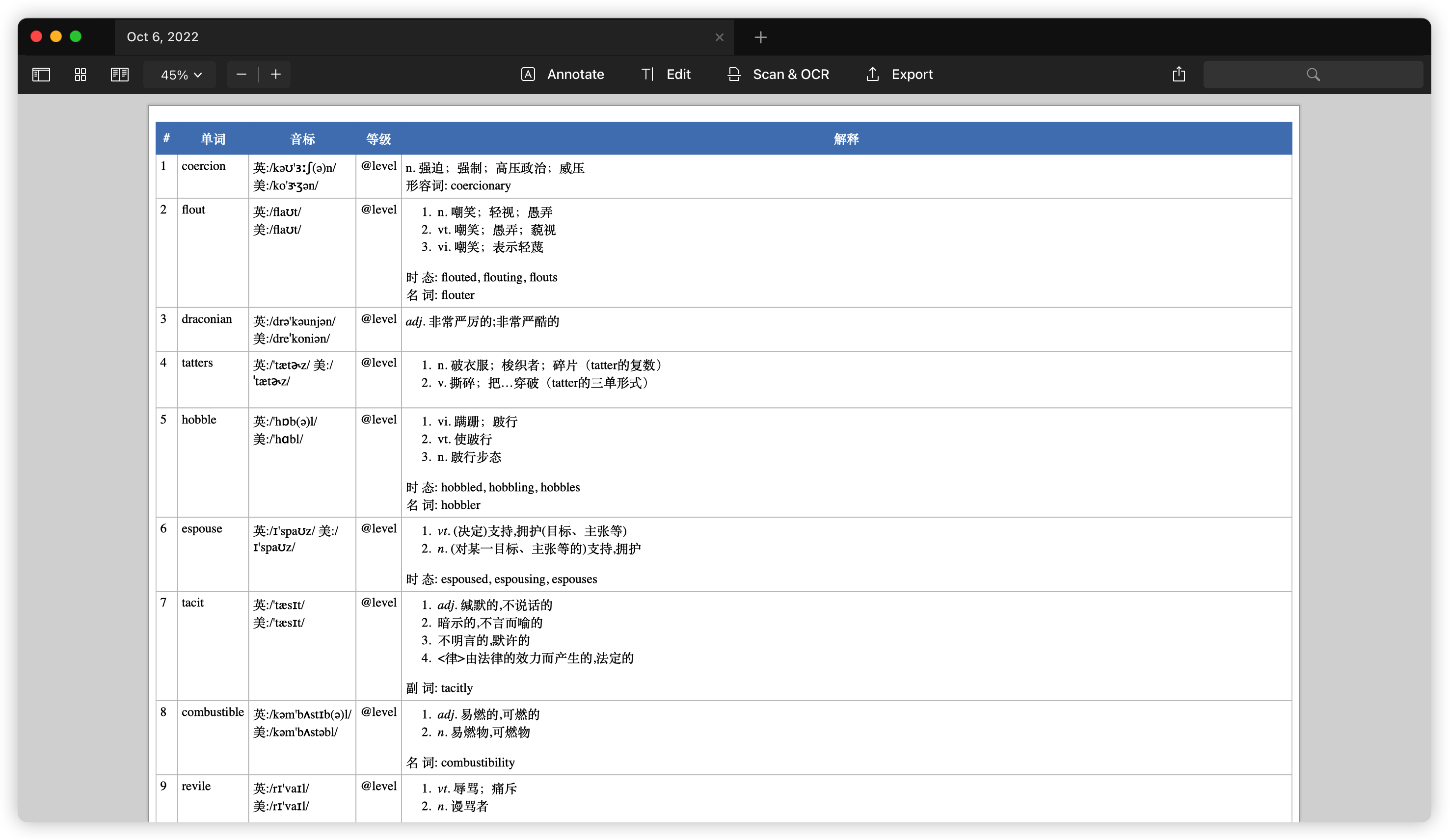
Words PDF
- View
- Table
- Sort by Date
- Filter by Category & From
- Board
- Group by Category
- Table
一些说明
总的来说,Database1设计的比较简单,仅保留了一些便于Filter和Sort的Properties。其中Category Board可以将自己阅读涉猎的领域作简单可视化,看看自己对哪些领域比较感兴趣,又对哪些方面的信息比较抗拒。
而阅读中对于语料的积累,都以pdf文件的方式将文章本体存档在对应文件夹内:
- 标注过的文章本体,裁切后以统一格式命名(收录在文件夹:外刊精读)
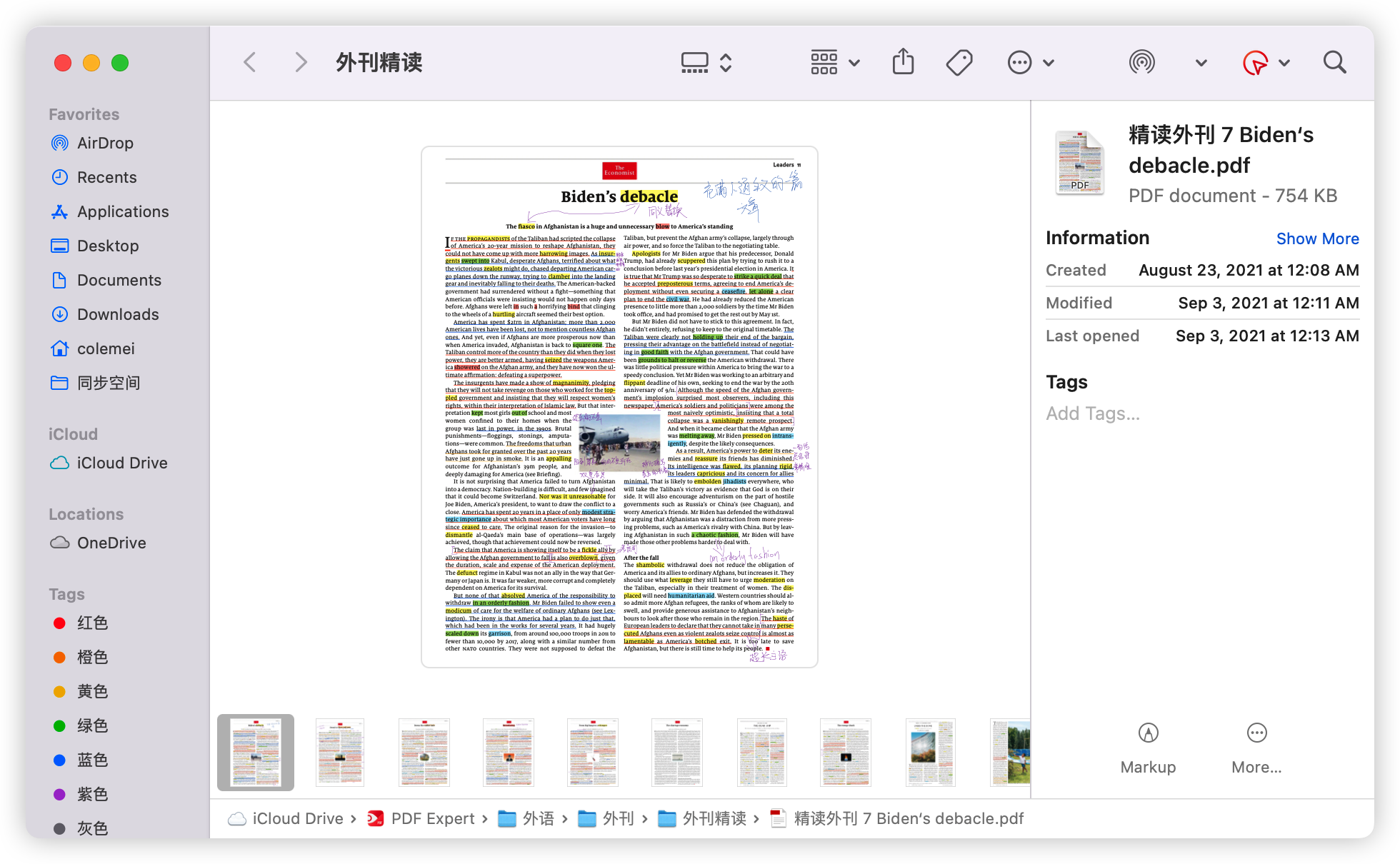
对文章本体的收录
- 生词(收录在文件夹:生词本)
Database2 (For Reading Type2)
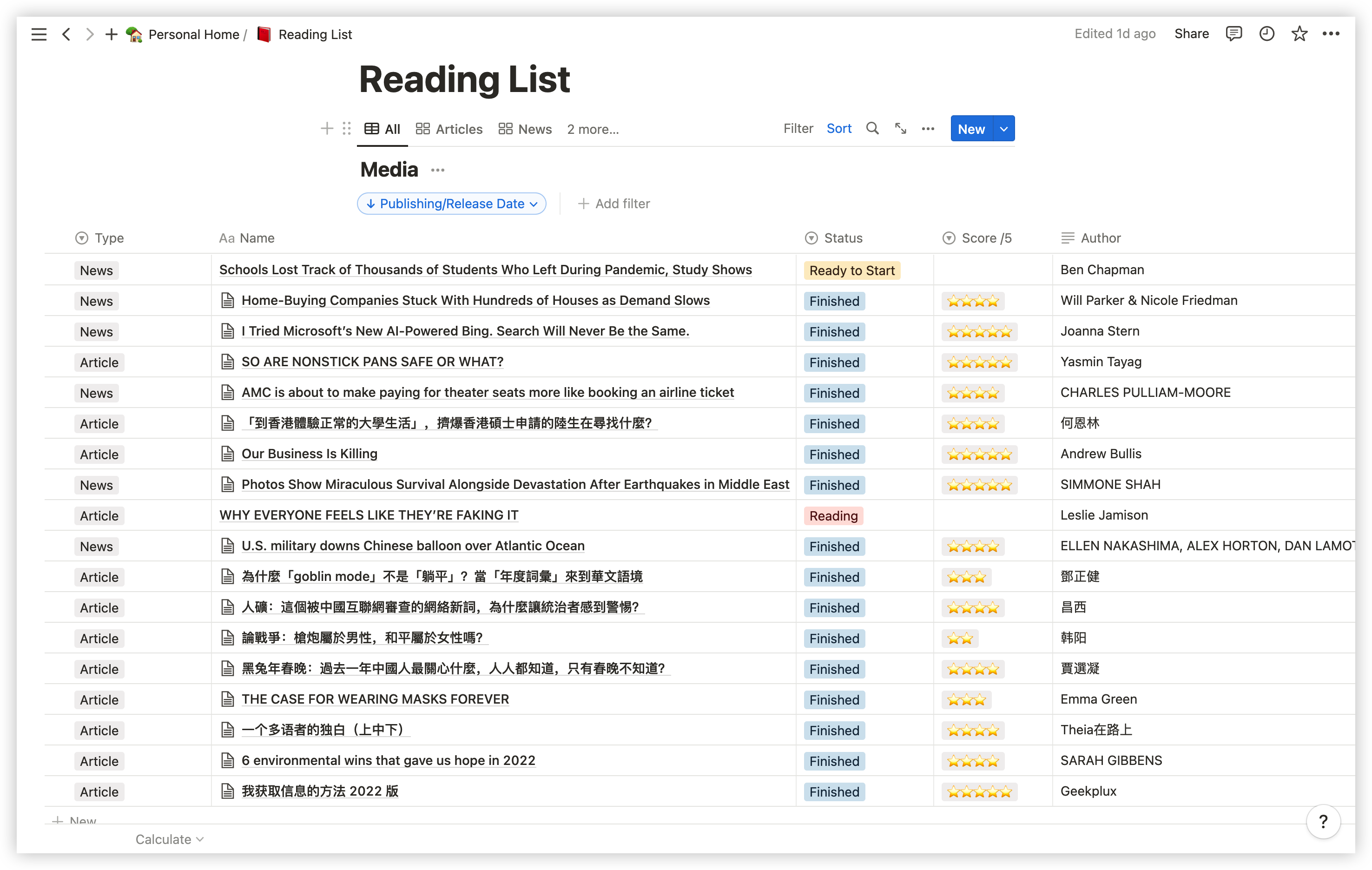
如图所示,在Database 2 “Reading List” 中,我作了如下设计:
Database2 TableView 01

Database2 TableView 02

Database2 Gallery for Articles

Database2 Gallery for News
Property
- Type:文章类型(Articles、News、Film&TV)
- Title:文章标题
- Status:阅读状态(按时态分为三种)
- Score/5:评价打分
- Author:作者
- Publisher:出版社
- Publishing/Release Date:发行日期
- Link:链接
- Summary:文章内容总结(一般是直接摘抄文章的Subtitle)
View
- Table for All
- Gallery for Articles
- Gallery for News
- Gallery for Film&TV
三种Gallery分别对应上面三种Type
一些说明
特别要强调的是,因为我也会阅读很多中文信息,所以本质上Reading List是我阅读各类信息的收录库,并不局限于英文信息。
可以看到,区别database 1,我对Property作了比较细致的划分,并增加了一些新的元素,像是比较主观的Score(对于不同的文章类型适用不同的打分标准);考虑到有的文章(像是某篇Essay或是项目的Document)不能一天读完,我引入了Status这一概念,由Ready to Start、Reading、Finished三个选项组成;还有像是Summary,它可以加速我完成对于信息的索引构建。
另外对于这一类阅读,将文章收录进数据库时,我还会将阅读时的一些摘录(在第二节的Type 2中讲到,由Paste实现)也一并誊抄进来,用quote block,并且用简短的一个或几个单词总结一下这段文字是在讲什么,像是这样:
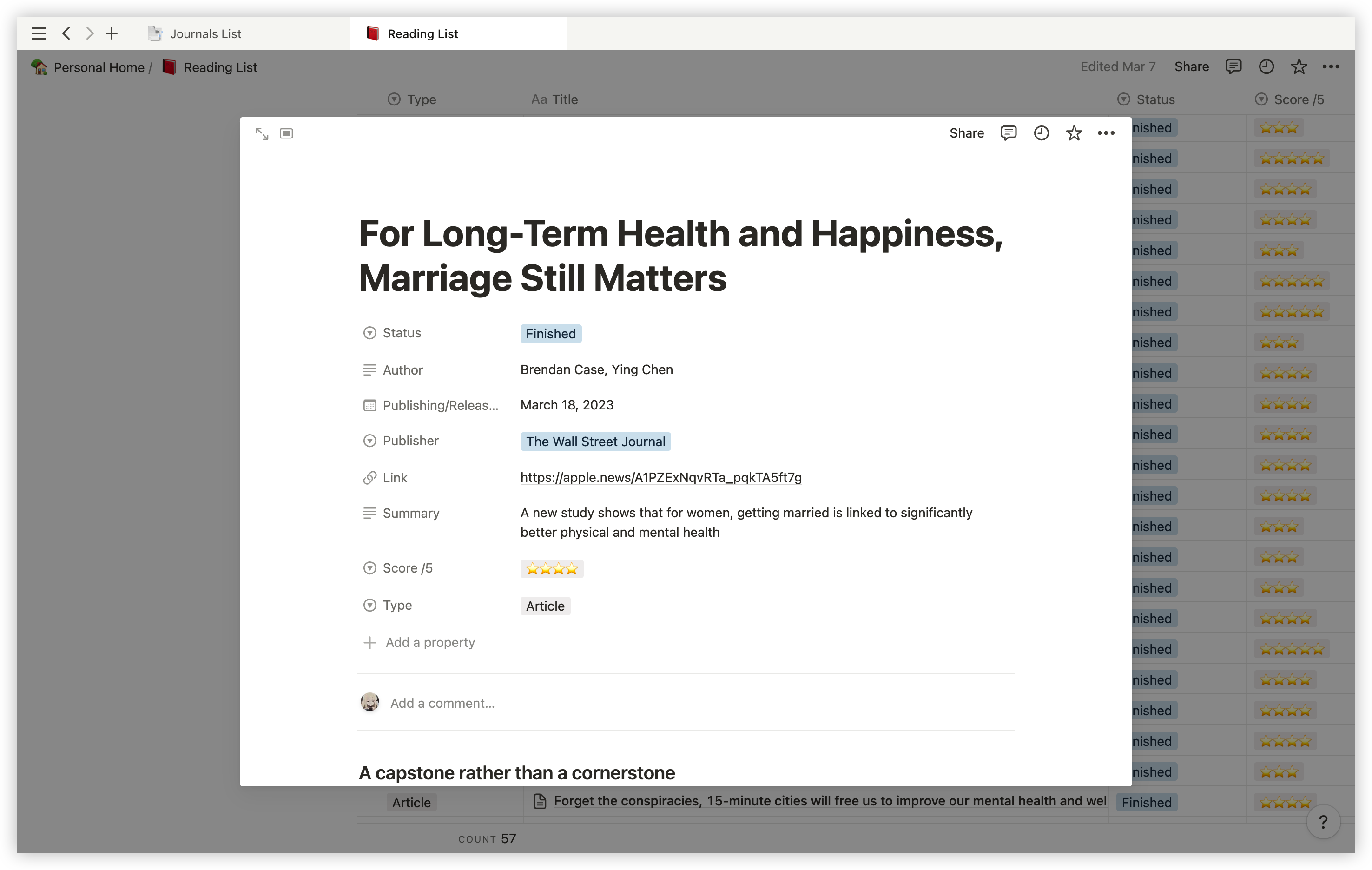
Outlook
Excerpt
相信我,搭配Gallery View可以将你的Collection打造得井然有序且质感十足。
小结
其实很多阅读工具中都自带一些类似的收录功能,像是Apple News+中的Saved Story和Hisroty、Reeder中的Star和Add to Read Later,甚至是Chrome中的Bookmark,Mail中的Flag。但是我还是更喜欢将不同平台,不同种类篇幅的信息作统一的收录,像是我在Notion的database中做的这样,毕竟术业有专攻嘛。